Introducción a Elasticsearch
06/10/2017Si seguís nuestro blog estaréis familiarizados con las búsquedas en el lenguaje SPARQL. Sin embargo, cuando tenemos que tratar directamente con texto, las búsquedas son más eficientes con otras tecnologías. Proyectos como Apache Lucene, Solr y Elasticsearch tienen como objetivo facilitar la búsqueda en texto. Un par de ejemplos de este tipo de tecnología se puede consultar en las concordancias de la Biblioteca Virtual Miguel de Cervantes o el buscador de datos de data.cervantesvirtual.com.
Inicialmente todo el mundo hablaba de Lucene que consiste en una librería Java donde todo se tiene que programar. A continuación, salió a la luz Solr que facilitaba la tarea proporcionando una dirección desde donde se podía indexar y buscar de una forma más intuitiva. Recientemente, empezamos a oír a hablar de Elasticsearch. No vamos a entrar en detalles sobre las diferencias y ventajas que aporta cada una de las opciones. Nuestra idea es proporcionar un pequeño ejemplo que permita poner de manifiesto en pocos minutos que Elasticsearch funciona y que cualquiera puede ponerse manos a la obra para crear un buscador que incluya funcionalidades a priori complejas como agrupaciones (o facets).
Elasticsearch se instala simplemente descargando la última versión, descomprimiendo el archivo y lanzado el comando elasticsearch desde la caperta bin.

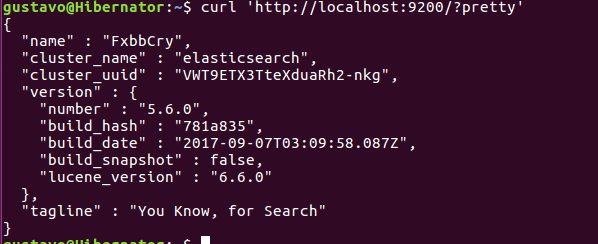
Una vez tenemos el servidor funcionando podemos comprobar en la url localhost:9200 que ya está funcionando:
Para que el tutorial tenga sentido vamos a intentar crear una aplicación que consuma datos reales mediante los cuales sea posible enlazar a los datos abiertos de la BVMC localizados en http://data.cervantesvirtual.com. Para ello, creamos una consulta SPARQL que devuelve los autores de la BVMC que se encuentran enlazados en Wikidata y recogemos información como año de nacimiento, año de fallecimiento, nombre, géneros, imagen y sexo. El resultado de la consulta lo descargamos en un fichero CSV que lo tenemos disponible en la cuenta de GitHub de la Fundación de la Biblioteca Virtual Miguel de Cervantes.
Existen numerosas librerías (javascript, python, Java,…) para la gestión de información con Elasticsearch. En este caso hemos realizado el ejemplo con el lenguaje de programación python. El código lo podéis descargar en GitHub en la siguiente dirección. y se puede lanzar ejecutando en nuestra consola python wikidata-authors.py. Sin entrar en detalle, el código lee el fichero CSV, crea un índice llamado «data» con información de tipo autor e indexa cada una de las filas del fichero CSV. Si os fijáis, el fichero CSV tiene sobre 6,000 líneas que consigue indexar en unos segundos. Si lanzamos de nuevo el comando de consulta podremos ver la estructura de nuestro nuevo índice:

{
"data" : {
"aliases" : { },
"mappings" : {
"autor" : {
"properties" : {
"ano_fallecimiento" : {
"type" : "keyword"
},
"ano_nacimiento" : {
"type" : "keyword"
},
"bvmc_id" : {
"type" : "keyword"
},
"generos" : {
"type" : "keyword"
},
"imagen" : {
"type" : "text"
},
"nombre" : {
"type" : "text",
"fields" : {
"folded" : {
"type" : "text",
"analyzer" : "folding"
}
},
"analyzer" : "spanish"
},
"pais" : {
"type" : "keyword"
},
"sexo" : {
"type" : "keyword"
},
"wikidata_uri" : {
"type" : "text"
}
}
}
},
"settings" : {
"index" : {
"number_of_shards" : "1",
"provided_name" : "data",
"creation_date" : "1507197943707",
"analysis" : {
"analyzer" : {
"folding" : {
"filter" : [
"lowercase",
"asciifolding"
],
"tokenizer" : "standard"
}
}
},
"number_of_replicas" : "0",
"uuid" : "1cmDekQ6RHKFQiWmRON8DQ",
"version" : {
"created" : "5060099"
}
}
}
}
}
El resultado mostrado en el código anterior indica los campos que contiene el índice bajo el nombre de mappings. En el apartado settings se incluye el analizador para poder realizar búsquedas con acentos y sin ellos. Es necesario configurar el servidor de elasticsearch para permitir peticiones desde localhost y para ellos debemos añadir en la carpeta de elasticsearch/config/elasticsearch.yml las siguientes instrucciones:
http.cors.enabled: true http.cors.allow-origin: "/.*/" http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE http.cors.allow-headers: "X-Requested-With,X-Auth-Token,Content-Type, Content-Length, Authorization"
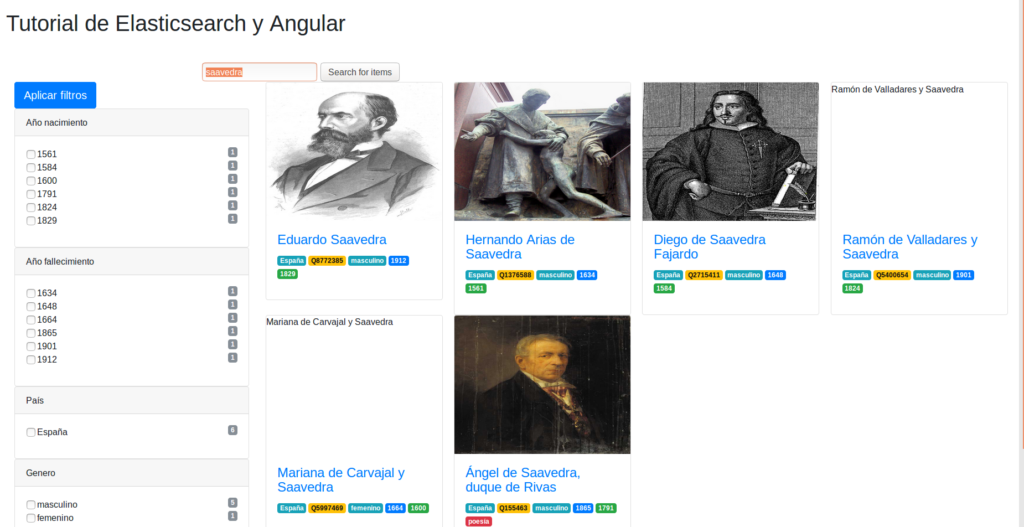
Para comprobar el funcionamiento hemos creado un pequeño ejemplo en angular que permite consultar y filtrar los resultados. Solo es necesario descargarlo y ejecutar bower install. A continuación abrimos en nuestro navegador index.html y veremos el buscador:
Hemos comprobado como podemos hacer una pequeña aplicación en 5 minutos utilizando las últimas tecnologías.
¡Espero que os haya gustado y os animo a participar en nuestro blog!